Python数据分析
Anaconda发行版
Jupyter notebook
安装和文档
启动
运行机制
主界面
新建文档
工作界面
文档结构
编辑和命令模式
快捷键
执行和输出
Markdown单元
图片和视频
幻灯片
导出格式
魔法命令
Numpy
基础知识
数据类型
创建数组
数组运算
通用函数
索引切片迭代
添加删除去重
形状变换
堆积数组
分割数组
视图和复制
广播机制
花式索引
布尔索引
统计方法
随机数
Pandas
Series
DataFrame
Index
重建索引
轴向上删除条目
索引和切片
算术和广播
函数和映射
排序和排名
统计和汇总
文件读取
分块读取
写出数据
JSON和Pickle
HDF5
EXCEL文件
Web交互
数据库交互
删除缺失值
补全缺失值
删除重复值
替换
重命名轴索引
离散化和分箱
检测和过滤
随机和抽样
字符串操作
分层索引
分层索引进阶
合并连接
粘合与堆叠
重塑
Matplotlib
配置环境
使用常识
保存图形
两种图画接口
使用中文
线型图
颜色线型和标记
坐标轴上下限
坐标轴刻度
图题、轴标签和图例
配置图题
配置图例
颜色条
文本、箭头和注释
散点图
直方图
条形图
饼图
误差线
等高线
多子图
patch
自定义坐标轴刻度
风格样式展示
下一步
散点图
阅读: 6558 评论:0与线型图类似的是,散点图也是一个个点集构成的。但不同之处在于,散点图的各点之间不会按照前后关系以线条连接起来。
- 用plt.plot画散点图
x = np.linspace(0,10,30) y = np.sin(x) plt.plot(x,y,'bo', ms=5)
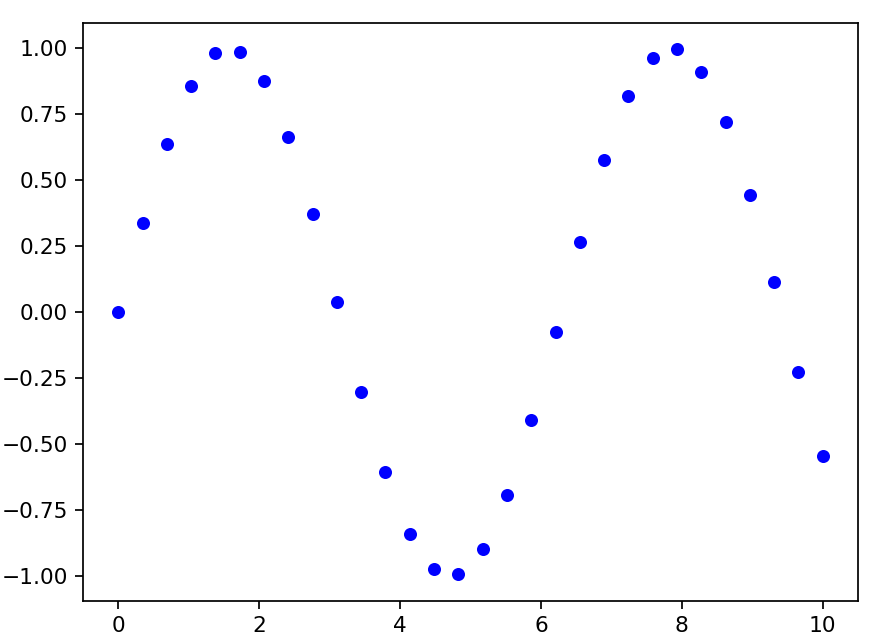
奇怪,代码和前面的例子差不多,为什么这里显示的却是散点图而不是sin曲线呢?原因有二:一是点集比较少,稀疏,才30个;二是没有指定线型。
- 用plt.scatter画散点图
scatter专门用于绘制散点图,使用方式和plot方法类似,区别在于前者具有更高的灵活性,可以单独控制每个散点与数据匹配,并让每个散点具有不同的属性。
一般使用scatter方法,如下例子就可以了:
plt.scatter(x, y, marker='o')
下面看一个随机不同透明度、颜色和大小的散点例子:
rng = np.random.RandomState(10) x = rng.randn(100) y = rng.randn(100) colors = rng.rand(100) sizes = 1000* rng.rand(100) plt.scatter(x, y, c=colors, s=sizes, alpha=0.3) plt.colorbar() # 绘制颜色对照条
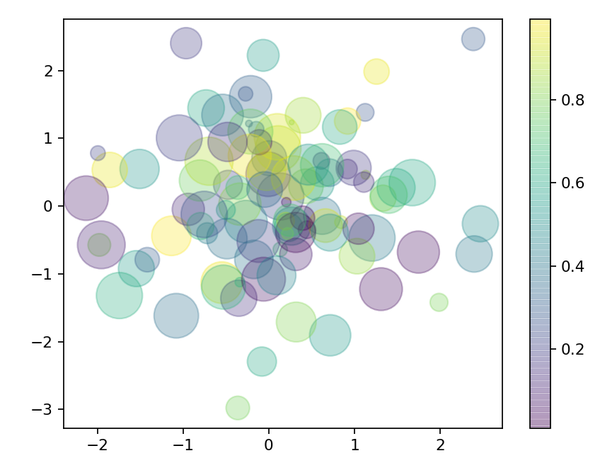
主要参数说明:
- x,y:输入数据
- s:标记大小,以像素为单位
- c:颜色
- marker:标记
- alpha:透明度
- linewidths:线宽
- edgecolors :边界颜色
上面的例子可以拓展到Scikit-learn中经典的鸢尾花iris数据来演示。
Iris数据集是常用的分类实验数据集,由Fisher在1936收集整理,是一类多重变量分析的数据集。数据集包含150个数据,分为3类,每类50个数据,每个数据包含4个属性。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
>>> from sklearn.datasets import load_iris >>> iris = load_iris() # 载入iris数据集 >>> iris # 查看一下 >>> iris.data # 查看一下 >>> iris.target # 查看一下 >>> iris.feature_names # 查看一下 >>> features = iris.data.T # 转置 >>> plt.scatter(features[0],features[1],alpha=0.2, s=100*features[3],c=iris.target) plt.xlabel(iris.feature_names[0]) plt.ylabel(iris.feature_names[1]);
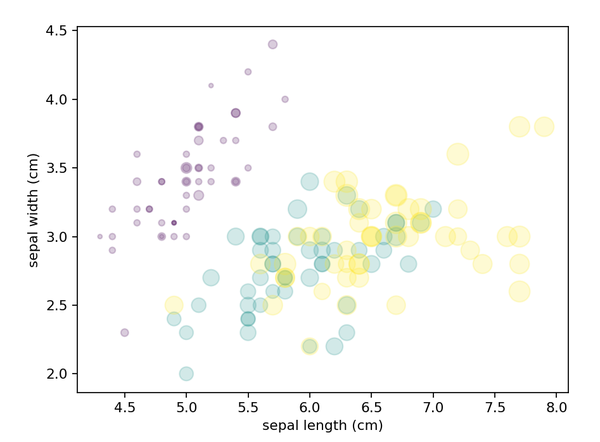
这个散点图让我们看到了不同维度的数据:每个点的坐标值x和y分别表示花萼的长度和宽度,点的大小表示花瓣的宽度,三种颜色对应三种不同类型的鸢尾花。这类多颜色多特征的散点图在探索和演示数据时非常有用。
在处理较少点集的时候scatter方法灵活度更高,可单独配置并渲染,但所需消耗的计算和内存资源也更多。当数据成千上万个之后,plot方法的效率更高,因为它对所有点使用一样的颜色、大小、类型等配置,自然更快。
scatter的更多内容请参考官网:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.scatter.html