列表
阅读: 39373 评论:15列表是Python中最基本也是最常用的数据结构之一。列表中的每个元素都被分配一个数字作为索引,用来表示该元素在列表内所排在的位置。第一个元素的索引是0,第二个索引是1,依此类推。
Python的列表是一个有序可重复的元素集合,可嵌套、迭代、修改、分片、追加、删除,成员判断。
从数据结构角度看,Python的列表是一个可变长度的顺序存储结构,每一个位置存放的都是对象的指针。
比如,对于这个列表 alist = [1, “a”, [11,22], {“k1”:”v1”}],其在内存内的存储方式是这样的:
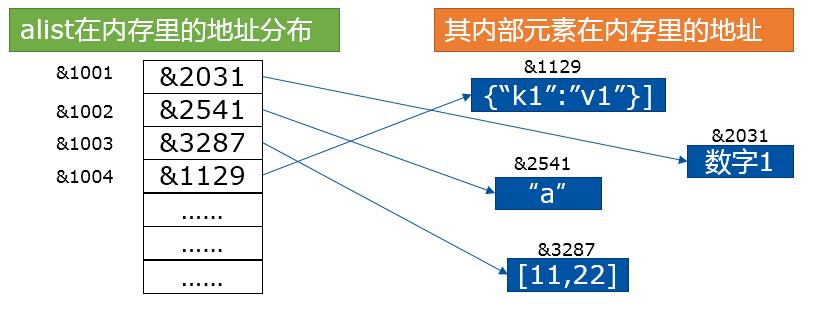
1. 创建方式
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。列表内的元素,可以是其它任意类型的数据,可多层嵌套列表,元素个数无限制。
>>> lis = [] # 创建一个空列表
>>> lis = [1, 2, 3]
>>> lis = [1, 'a', [11,22], {'k1':'v1'}]
>>> lis = [1, 2, [3, 4, 5]]
2. 访问列表内的元素
列表从0开始为它的每一个元素顺序创建下标索引,直到总长度减一。要访问它的某个元素,以方括号加下标值的方式即可。注意要确保索引不越界,一旦访问的 索引超过范围,会抛出异常。所以,一定要记得最后一个元素的索引是len(list)-1。
>>> lis = ["a", "b", "c"]
>>> lis[0]
'a'
>>> lis[1]
'b'
>>> lis[2]
'c'
>>> lis[3]
Traceback (most recent call last):
File "<pyshell#7>", line 1, in <module>
lis[3]
IndexError: list index out of range
3. 修改元素的值
直接对元素进行重新赋值。
>>> lis[0] 'a' >>> lis[0] = "d" >>> lis[0] 'd'
4. 删除元素
使用del语句或者remove(),pop()方法删除指定的元素。
>>> lis = ["a", "b", "c"]
>>> del lis[0]
>>> lis
['b', 'c']
>>> lis.remove("b")
>>> lis
['c']
>>> lis.pop()
'c'
>>> lis
[]
5. 列表的特殊操作
除了以上的常规操作,列表还有很多有用的其它操作。
| 语句 | 结果 | 描述 |
|---|---|---|
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合两个列表 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 列表的乘法 |
| 3 in [1, 2, 3] | True | 判断元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代列表中的每个元素 |
6. 针对列表的常用函数
Python有很多内置函数,可以操作列表。
| 函数 | 作用 |
|---|---|
| len(list) | 返回列表元素个数,也就是获取列表长度 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将序列转换为列表 |
让我们看一些例子:
>>> s = [1, 4, 9, 16, 25]
>>> len(s)
5
>>> max(s)
25
>>> min(s)
1
>>> s = list((1, "a", "b", 2))
>>> s
[1, 'a', 'b', 2]
>>> max(s) # 不能混合不同类型进行最大最小求值
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
max(s)
TypeError: '>' not supported between instances of 'str' and 'int'
这些操作都不会修改列表本身,属于安全操作。max、min在Python3中,不能对不同类型的对象进行大小的比较了。
7. 切片
切片指的是对序列进行截取,选取序列中的某一段。
切片的语法是: list[start:end]
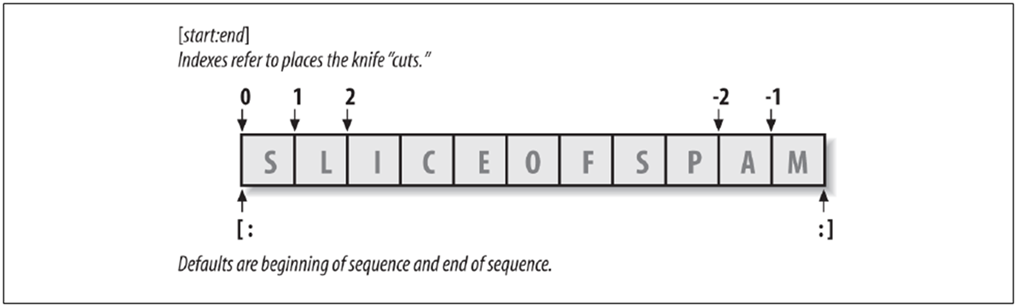
以冒号分割索引,start代表起点索引,end代表结束点索引。省略start表示以0开始,省略end表示到列表的结尾。注意,区间是左闭右开的!也就是说[1:4]会截取列表的索引为1/2/3的3个元素,不会截取索引为4的元素。分片不会修改原有的列表,可以将结果保存到新的变量,因此切片也是一种安全操作,常被用来复制一个列表,例如newlist = lis[:]。
如果提供的是负整数下标,则从列表的最后开始往头部查找。例如-1表示最后一个元素,-3表示倒数第三个元素。
切片过程中还可以设置步长,以第二个冒号分割,例如list[3:9:2],表示每隔多少距离取一个元素。
下面是一些例子,让你有更清晰的了解。
>>> a = [1,2,3,4,5,6,7,8,9,10] >>> a[3:6] [4, 5, 6] >>> a[:7] [1, 2, 3, 4, 5, 6, 7] >>> a[2:] [3, 4, 5, 6, 7, 8, 9, 10] >>> s = a[:] >>> s [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> a [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> s.remove(4) >>> s [1, 2, 3, 5, 6, 7, 8, 9, 10] >>> a [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> a[-1] 10 >>> a[-3] 8 >>> a[-5:] [6, 7, 8, 9, 10] >>> a[::-1] [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] >>> a[1:8:2] [2, 4, 6, 8] >>> a[1:8:-2] [] >>> a[-8::-2] [3, 1] >>> a[-8::2] [3, 5, 7, 9]
8. 多维列表(嵌套列表)
列表可以嵌套列表,形成多维列表,形如矩阵。其元素的引用方法是list[i][j][k].....。当然,也可以嵌套别的数据类型。
>>> a = [[1,2,3],[4,5,6],[7,8,9]]
>>> a[0][1]
2
>>> a = [[1,2,3],[4,5,6],[7,8,9],{"k1":"v1"}]
>>> a[3]["k1"]
'v1'
9. 列表的遍历
列表有好几种遍历方式:
a = [1,2,3,4,5,6] --------------------------- for i in a: # 遍历每一个元素本身 print(i) ------------------------------ for i in range(len(a)): # 遍历列表的下标,通过下标取值 print(i, a[i]) -------------------------------- x = 9 if x in a: # 进行是否属于列表成员的判断。该运算速度非常快。 print("True") else: print("False")
10. 列表的内置方法
下图中的方法是列表专有的内置方法,请熟记于心。
| 方法 | 作用 |
|---|---|
| append(obj) | 在列表末尾添加新的对象 |
| count(obj) | 统计某个元素在列表中出现的次数 |
| extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| insert(index, obj) | 将对象插入列表 |
| pop(obj=list[-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| remove(obj) | 移除列表中某个值的第一个匹配项 |
| reverse() | 反向列表中元素 |
| sort([func]) | 对原列表进行排序 |
| copy() | 复制列表 |
| clear() | 清空列表,等于del lis[:] |
注意:其中的类似 append,insert, remove 等方法会修改列表本身,并且没有返回值(严格的说是返回None)。
注意例子中的lis变量,不要写成list了。有些发生错误的地方是错误用法展示,仔细看为什么错了。
>>> lis = ["a", "b", "c", "d"] >>> lis.append("A") >>> lis ['a', 'b', 'c', 'd', 'A'] >>> lis.count() Traceback (most recent call last): File "<pyshell#3>", line 1, in <module> lis.count() TypeError: count() takes exactly one argument (0 given) >>> lis.count("a") 1 >>> lis.extend(["a","b"]) >>> lis ['a', 'b', 'c', 'd', 'A', 'a', 'b'] >>> lis.count("a") 2 >>> lis.index("a") 0 >>> lis.index("A") 4 >>> lis.insert(3, "E") >>> lis ['a', 'b', 'c', 'E', 'd', 'A', 'a', 'b'] >>> s = lis.pop() >>> s 'b' >>> lis ['a', 'b', 'c', 'E', 'd', 'A', 'a'] >>> s = lis.pop(4) >>> s 'd' >>> lis ['a', 'b', 'c', 'E', 'A', 'a'] >>> lis.remove(3) Traceback (most recent call last): File "<pyshell#19>", line 1, in <module> lis.remove(3) ValueError: list.remove(x): x not in list >>> lis.remove("E") >>> lis ['a', 'b', 'c', 'A', 'a'] >>> lis.reverse() >>> lis ['a', 'A', 'c', 'b', 'a'] >>> newlis = lis.copy() >>> lis ['a', 'A', 'c', 'b', 'a'] >>> newlis ['a', 'A', 'c', 'b', 'a'] >>> newlis.clear() >>> newlis [] >>> lis.sort() >>> lis ['A', 'a', 'a', 'b', 'c']
11. 将列表当做堆栈
Python的列表特别适合也很方便作为一个堆栈来使用。堆栈是一种特定的数据结构,最先进入的元素最后一个被释放(后进先出)。将列表的表头作为栈底,表尾作为栈顶,就形成了一个堆栈。用列表的append()方法可以把一个元素添加到堆栈顶部(实际上就是在列表的尾部添加一个元素)。用不指定索引的pop()方法可以把一个元素从堆栈顶释放出来(也就是从列表尾部弹出一个元素)。例如:
>>> stack = [3, 4, 5] >>> stack.append(6) >>> stack.append(7) >>> stack [3, 4, 5, 6, 7] >>> stack.pop() 7 >>> stack [3, 4, 5, 6] >>> stack.pop() 6 >>> stack.pop() 5 >>> stack [3, 4]
列表在内存内部是顺序存储结构的,所以在其尾部的添加和删除动作,也就是append和pop方法的效率非常高,具备随机存取速度,也就是O(1)的时间复杂度,因此用作堆栈是再合适不过了。
12. 将列表当作队列
也可以把列表当做队列用。队列是一种先进先出的数据结构。但是用Python的列表做队列的效率并不高。因为,虽然在列表的最后添加或者弹出元素速度很快,但在列头部弹出第一个元素的速度却不快(因为所有其他的元素都得跟着一个一个地往左移动一位)。通常我们使用queue.Queue作为单向队列,使用collections.deque作为双向队列。
谢谢博主,学到了很多。
省略start表示以0开始,省略end表示到列表的结尾。 省略结尾时,截取时,也是要最后一个元素的。
有一个错误,方法clear()清空列表,等于del lis[:],clear后列表还存在,del后变量直接从内存消失了
再试试^-^
pop默认删除组后一个元素
>>> a = [1,2,3,4,5,6,7,8,9,10] >>> a[-3:-8:-1] #这样可以实现逆序提取元素个数 [8, 7, 6, 5, 4] >>> a[-3:-8] #光这样是不行的 [] >>> a[3:8] #标准的从左向右提取啦哈哈 [4, 5, 6, 7, 8]
因为切片的默认步长是1
a[:]是复制一个列表, 删除一个复制的列表,却变成了clear...
pop是有返回值的,不是None
File "", line 1 list1= [1, “a”,[11,22],[“k1”:”v1”]] ^ SyntaxError: invalid character in identifier python3 语法错误
在使用例子的时候,要自己手动敲入字符。不要直接拷贝网页上的内容。
字典用的是花括号,不是方括号
多维列表 第一个例子错了吧
下标索引写错了,已修改。
谢谢博主