验证器
阅读: 43515 评论:1在Django的模型字段参数中,有一个参数叫做validators,这个参数是用来指定当前字段需要使用的验证器,也就是对字段数据的合法性进行验证,比如大小、类型等。
Django的验证器可以分为模型相关的验证器和表单相关的验证器,它们基本类似,但在使用上有区别。
本文讨论的是模型相关的验证器。
一、自定义验证器
一个验证器其实就是一个可调用的对象(函数或类),接收一个初始输入值作为参数,对这个值进行一系列逻辑判断,如果不满足某些规则或者条件,则表示验证不通过,抛出一个ValidationError异常。如果满足条件则通过验证,不返回任何内容(也就是默认的return None),可以继续下一步。
验证器具有重要作用,可以被重用在别的字段上,是工具类型的逻辑封装。
下面是一个验证器的例子,它只允许偶数通过验证:
from django.core.exceptions import ValidationError from django.utils.translation import gettext_lazy as _ def validate_even(value): if value % 2 != 0: raise ValidationError( _('%(value)s is not an even number'), params={'value': value}, )
通过下面的方式,将偶数验证器应用在字段上:
from django.db import models class MyModel(models.Model): even_field = models.IntegerField(validators=[validate_even])
因为验证器运行之前,(输入的)数据会被转换为 Python 对象,因此我们可以将同样的验证器用在 Django form 表单中(事实上Django为表单提供了另外一些验证器):
from django import forms class MyForm(forms.Form): even_field = forms.IntegerField(validators=[validate_even])
你还可以通过Python的魔法方法__cal__()编写更复杂的可配置的验证器,比如Django内置的RegexValidator验证器就是这么干的。
验证器也可以是一个类,但这时候就比较复杂了,需要确保它可以被迁移框架序列化,确保编写了deconstruction()和__eq__()方法。这种做法很难找到参考文献和博文,要靠自己摸索或者研究DJango源码。
二、工作机制
让我们来测试一下上面写的验证器:
>>> from .models import MyModel >>> a = MyModel.objects.create(even_field=3) >>> a <MyModel: MyModel object (1)> >>> a.even_field 3
什么?!!!不是说只有偶数才能通过验证吗?这里我提供了数字3,可是为什么创建成功了??
我们接着在admin站点中注册MyModel模型,然后在图形化界面后台中创建MyModel的实例,你会发现这个时候验证器起作用了,奇数是无法通过表单验证的!
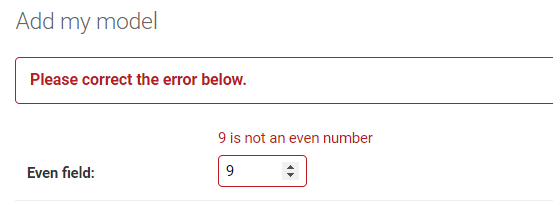
为什么会这样??
这就要从Django的源码说起!
Django是这么设计的:
- 模型的验证器不会在调用save()方法的时候自动执行
- 表单的验证器会在调用save()方法的时候自动执行
为什么这么设计?个人猜测,Django官方为了序列化、链式调用等功能的兼容性,没有自动进行验证操作。
这个设计在源码中是怎么体现的?
- Django的模型相关源码中,没有
is_valid()方法,也不会自动调用full_clean()方法,所以Django不会自动进行模型验证。但是它依然提供了四个重要的验证方法,也就是full_clean()、clean_fields()、clean()和validate_unique(),一会细说 - Django的表单系统forms的相关源码中,表单在save之前会自动执行一个
is_valid()方法,这个方法里会调用验证器。
表单的内容在其它章节中讲解。
下面介绍Django模型的验证步骤和四个方法:
模型验证的步骤:
- 如果你手动调用了
full_clean()方法,那么会依次自动调用下面的三个方法 clean_fields():验证各个字段的合法性clean():验证模型级别的合法性validate_unique():验证字段的独一无二性
本质上,后面三个方法是具体实现,full_clean()是领头羊,实际操作中,你完全可以具体使用其中一个或多个。用了full_clean()就等于后面三个都用。
full_clean()
签名:Model.full_clean(exclude=None, validate_unique=True)
- exclude用于指定某些字段不进行验证,也就是所谓的例外字段
- validate_unique用于指定是否调用
validate_unique()方法
让我们看下它的源代码:
def full_clean(self, exclude=None, validate_unique=True): errors = {} if exclude is None: exclude = [] else: exclude = list(exclude) try: self.clean_fields(exclude=exclude) #1 except ValidationError as e: errors = e.update_error_dict(errors) try: self.clean() #2 except ValidationError as e: errors = e.update_error_dict(errors) if validate_unique: for name in errors: if name != NON_FIELD_ERRORS and name not in exclude: exclude.append(name) try: self.validate_unique(exclude=exclude) #3 except ValidationError as e: errors = e.update_error_dict(errors) if errors: raise ValidationError(errors)
可以看出,它依次调用了其它三个方法,如果最后的errors中有内容,则抛出ValidationError异常。
我们最好不要去修改full_clean()方法的源代码,一般也不用重写它,直接调用即可。
模型的save()方法不会自动调用full_clean()方法,你必须手动调用。
如果调用验证器后,抛出ValidationError异常,Django会将所有的异常信息放置在e.message_dict字典中供使用。比如下面的例子:
# 在视图中我们可以这么做 from django.core.exceptions import ValidationError try: article.full_clean() except ValidationError as e: # 在这里做一些异常处理操作 pass
在模型定义中我们可以如下重写save()方法,实现自动验证功能,不需要在视图中反复调用了:
# models.py from django.core.exceptions import ValidationError from django.utils.translation import gettext_lazy as _ def validate_even(value): if value % 2 != 0: raise ValidationError( _('%(value)s is not an even number'), params={'value': value}, ) from django.db import models class MyModel(models.Model): even_field = models.IntegerField(validators=[validate_even]) def save(self, *args, **kwargs): # 重写save方法是关键 try: self.full_clean() super().save(*args, **kwargs) except ValidationError as e: print('模型验证没通过: %s' % e.message_dict)
执行过程展示:
>>> from .models import MyModel >>> a = MyModel.objects.create(even_field=5) 模型验证没通过: {'even_field': ['5 is not an even number']}
这样,我们就实现了自动的模型验证。
小技巧:可以通过打印e来查看,Django怎么封装的错误信息,给我们提供了哪些键值,比如上例中,我们可以使用e.message_dict['even_field']。
clean_fields()
签名:Model.clean_fields(exclude=None)
参数同上,看下它的源代码:
def clean_fields(self, exclude=None): if exclude is None: exclude = [] errors = {} for f in self._meta.fields: if f.name in exclude: continue raw_value = getattr(self, f.attname) if f.blank and raw_value in f.empty_values: continue try: setattr(self, f.attname, f.clean(raw_value, self)) #核心是这一句 except ValidationError as e: errors[f.name] = e.error_list if errors: raise ValidationError(errors)
我们最好也不要去修改和重写它的源代码。
这个方法本质上就是循环模型中的所有字段,找出其中定义了验证器的那些,并执行它们。
我们前面自定义的偶数验证器,其实就是在这里被调用的。
clean()
这个方法很特别,我们看看它的源代码:
def clean(self): """ Hook for doing any extra model-wide validation after clean() has been called on every field by self.clean_fields. Any ValidationError raised by this method will not be associated with a particular field; it will have a special-case association with the field defined by NON_FIELD_ERRORS. """ pass
什么都没有!实际上,这个方法是给你留了个钩子,你需要重写它,然后在里面编写模型级别的验证,比如修改模型的属性,以及跨字段相关的验证逻辑。
下面我们通过一个例子来展示它的用法:
import datetime from django.core.exceptions import ValidationError from django.db import models from django.utils.translation import gettext_lazy as _ class Article(models.Model): content = models.TextField() status = models.CharField(max_length=32) pub_date = models.DateField(blank=True, null=True) def clean(self): # 不允许草稿文章具有发布日期字段 if self.status == '草稿' and self.pub_date is not None: raise ValidationError(_('草稿文章尚未发布,不应该有发布日期!')) # 如果已发布的文章还没有设置发布日期,则将发布日期设置为当天 if self.status == '已发布' and self.pub_date is None: self.pub_date = datetime.date.today() # 更多Django技术文章请访问https://www.liujiangblog.com
说明:
- gettext_lazy在这里无关紧要
- 在Article模型中重写了clean方法,它不需要接受其它参数
- 第一个if判断,不允许草稿文章具有发布日期字段。如果你提供了,对不起,抛出ValidationError异常
- 第二个if判断,如果已发布的文章还没有设置发布日期,则将发布日期设置为当天
- 这是一个跨字段的,全局性的验证方法,它不像我们一开始自定义的验证器那样,不是作为一个验证器参数进行提供,而是写在clean方法中了,一定要注意区别。
clean()方法写好了,我们就可以在Article模型中重写save()方法了:
def save(self, *args, **kwargs): from django.core.exceptions import NON_FIELD_ERRORS try: self.full_clean() super().save(*args, **kwargs) except ValidationError as e: print('验证没通过: %s' % e.message_dict[NON_FIELD_ERRORS])
注意:这里我们导入了NON_FIELD_ERRORS,在最后打印了e.message_dict[NON_FIELD_ERRORS],这是为什么呢?
因为,clean()中编写的都是模型级别、跨字段的验证方法,没有具体和某个字段绑定,所以Django提供了一个NON_FIELD_ERRORS关键字,用来说明这不是某个字段引起的异常,而是非字段相关的错误。
如果你非要将错误定位到某个具体的字段,也不是不可以的,如下例子所示:
class Article(models.Model): ... def clean(self): if self.status == '草稿' and self.pub_date is not None: raise ValidationError({'pub_date': _('草稿文章尚未发布,不应该有发布日期!')}) ...
甚至,你可以如下方式,映射字段和错误信息:
raise ValidationError({ 'title': ValidationError(_('Missing title.'), code='required'), 'pub_date': ValidationError(_('Invalid date.'), code='invalid'), })
这些技巧,本质上就是给ValidationError异常类提供信息参数。
validate_unique()
签名:Model.validate_unique(exclude=None)
它的源代码也很简单:
def validate_unique(self, exclude=None): unique_checks, date_checks = self._get_unique_checks(exclude=exclude) errors = self._perform_unique_checks(unique_checks) date_errors = self._perform_date_checks(date_checks) for k, v in date_errors.items(): errors.setdefault(k, []).extend(v) if errors: raise ValidationError(errors)
这个方法类似clean_fields(),只不过它只用来验证模型中的唯一性约束是否满足,而不是字段的值是否满足验证需求。
如果你提供了exclude参数,那么该参数包含的所有字段都不会进行唯一性验证。
我们最好也不要去修改和重写它的源代码。
总结
Django中模型验证器的使用套路:
- 编写字段级别的验证器,在字段中作为参数指定
- 或者编写clean()方法,实现模型级别、跨字段的验证功能
- 重写save()方法,调用
full_clean(),实现全自动的验证 - 或者在视图中,通过模型实例调用
full_clean()方法,实现手动验证
三、内置验证器
验证器的作用很重要,需求也很广泛,Django为此内置了一些验证器,我们直接拿来使用即可:
RegexValidator
这是正则匹配验证器。用于对输入的值进行正则搜索,如果命中,则平安无事,如果没命中则弹出 ValidationError 异常。
数字签名:class RegexValidator(regex=None, message=None, code=None, inverse_match=None, flags=0)
参数说明:
- regex:用于匹配的正则表达式
- message:自定义异常错误信息。默认是
"Enter a valid value" - code:自定义错误码。默认是
"invalid" - inverse_match:将通过和不通过验证的判断逻辑反转。也就是未命中则平安,命中则出错。
- flags:编译正则表达式时使用的正则flags。默认为0。
EmailValidator
数字签名:class EmailValidator(message=None, code=None, whitelist=None)
邮件格式验证器。
参数说明:
- message: 自定义错误信息,默认为 "Enter a valid email address"。
- code: 自定义错误码,默认为"invalid"。
- whitelist:邮件域名白名单,默认为
['localhost']。
URLValidator
数字签名:class URLValidator(schemes=None, regex=None, message=None, code=None)
RegexValidator的子类,用于验证url的格式是否正确。
schemes:指定URL/URI的协议模式,默认值为['http', 'https', 'ftp', 'ftps']
validate_email
EmailValidator的一个实例,未做任何自定义。
validate_slug
一个确保输入值是字母、数字、下划线和连字符组合的RegexValidator的实例。
validate_unicode_slug
上面的Unicode编码版本
validate_ipv4_address
一个RegexValidator的实例,用于判断输入值是否为ipv4格式
validate_ipv6_address
上面的ipv6版本
validate_ipv46_address
同时支持ipv4和ipv6
validate_comma_separated_integer_list
判断输入是否是一个以逗号分隔的数字列表,一个RegexValidator的实例。
int_list_validator
数字签名:int_list_validator(sep=', ', message=None, code='invalid', allow_negative=False)
判断一个由数字组成的字符串是否以指定的sep分隔。allow_negative用于反转判断逻辑。
MaxValueValidator
签名:class MaxValueValidator(limit_value, message=None)
是否超过指定最大值
MinValueValidator
签名:class MinValueValidator(limit_value, message=None)
是否小于指定的最小值
MaxLengthValidator
签名:class MaxLengthValidator(limit_value, message=None)
输入值的长度是否超过限定值
MinLengthValidator
输入值的长度是否小于限定值
DecimalValidator
签名:lass DecimalValidator(max_digits, decimal_places)
数字验证器。当发生下面情况时弹出异常:
- 输入值超过max_digits
- 输入值的位数超过decimal_places
- 输入值大于最大位数与小数位数之差。(待确认)
FileExtensionValidator
签名:class FileExtensionValidator(allowed_extensions, message, code)
文件扩展名不在合法性列表中。合法性列表通过参数allowed_extensions指定。
validate_image_file_extension
通过pillow库确定一个图片文件的扩展名是合法的
ProhibitNullCharactersValidator
签名:class ProhibitNullCharactersValidator(message=None, code=None)
对输入值进行 str(value) 操作,转换成字符串,然后如果这个字符串中包含1个以上的空字符'\x00',则验证失败。
四、有帮助的ValidationError
当验证失败,弹出ValidationError异常时,赋予异常更好更准确的说明信息是一件非常有价值的事。
下面列举了一些好的和坏的做法对比。
- 为异常提供说明性的错误码
```python # Good ValidationError(_('Invalid value'), code='invalid')
# Bad ValidationError(_('Invalid value')) ```
- 使用params参数构造错误信息字符串
```python # Good ValidationError( _('Invalid value: %(value)s'), params={'value': '42'}, )
# Bad ValidationError(_('Invalid value: %s') % value) ```
- 使用关键字参数,而不是位置参数
```python # Good ValidationError( _('Invalid value: %(value)s'), params={'value': '42'}, )
# Bad ValidationError( _('Invalid value: %s'), params=('42',), ) ```
- 用
gettext方法将字符串包裹起来,方便语言转换:
```python # Good ValidationError(_('Invalid value'))
# Bad ValidationError('Invalid value') ```
综合在一起,推荐的例子:
raise ValidationError( _('Invalid value: %(value)s'), code='invalid', params={'value': '42'}, )
当需要同时展示多个验证错误的时候:
# 好的做法 raise ValidationError([ ValidationError(_('Error 1'), code='error1'), ValidationError(_('Error 2'), code='error2'), ]) # 差的做法 raise ValidationError([ _('Error 1'), _('Error 2'), ])
在pycharm或中创建python包可以直接生成一个空__init__.py模块